Die wissenschaftliche Methode des distant reading bezeichnet ein Prinzip, viele Texte in einem Textkorpus gleichzeitig ins Visier zu nehmen, statt sich auf jeden einzelnen Text zu fokussieren. Die Grundlage dafür ist üblicherweise das Zählen beziehungsweise das Umwandeln der Wörter in Zahlen und Vektoren. Mit speziellen Algorithmen, die darauf spezialisiert sind, Merkmale in Texten zu erkennen, werden anschließend unterschiedliche Analysen durchgeführt.
Aber warum denn auf einmal distant reading, wenn wir ja seit Jahrhunderten ganz gut auch ohne klargekommen sind? Sind wir plötzlich zu faul für das Lesen geworden und überlassen es deswegen lieber den Maschinen? Natürlich ist das nicht der Fall. Distant reading ist nämlich kein Ersatz für das Lesen, sondern es eröffnet eine neue, ergänzende Perspektive auf den Text. Während close reading (das konzentrierte Lesen eines Textes) als werkzentrierter Ansatz der Literaturwissenschaft auf einzelne Texte genau eingeht, ist distant reading ein Weg, große Textkorpora in ihrer Gesamtheit zu erforschen. Zusätzlich zu close und distant gibt es auch Begriffe wie blended (gemischtes) oder scalable reading (skaliertes Lesen), die für eine Kombination aus nahem und entferntem Lesen stehen. Keines dieser Konzepte kommt ohne die fachliche Expertise aus, da Wörter zählen und auswerten, ohne den Kontext zu verstehen, nicht ausreicht, um wissenschaftliche Erkenntnisse zu erlangen: Dieser Forschungsbereich ist ein klassisches Szenario für die wechselseitige Bereicherung digitaler Methoden und geisteswissenschaftlicher Expertise im Sinne des Medientheoretikers Clemens Apprich.
Von den Spectators zu Distant Spectators
Ein Beispiel für das erfolgreiche und aufschlussreiche Zusammenspiel zwischen nah und fern bietet die digitale Edition Die "Spectators" im internationalen Kontext, ein seit 2010 stetig weiterentwickeltes Kooperationsprojekt des Instituts für Romanistik und des Zentrums für Informationsmodellierung der Universität Graz. Die Edition widmet sich den Moralischen Wochenschriften, einer speziellen Gattung von Zeitschriften des 18. Jahrhunderts, die Ideen der Aufklärung, wie Moral, Tugendhaftigkeit und gesellschaftliches Zusammenleben, an ein nicht-akademisches Publikum vermittelte. Die zunächst in England entstandenen Spectators fanden rasch Nachahmung auf dem europäischen Festland: Die Zeitschriften wurden übersetzt, imitiert und adaptiert. Über 3.500 Einzelausgaben von knapp 70 Zeitschriften in sechs Sprachen stehen interessierten Leserinnen und Lesern im Geisteswissenschaftlichen Asset Management System (GAMS) zur Verfügung.

Die Texte wurden mittels eines XML-Standard kodiert und damit maschinenlesbar gemacht. Dabei wurde nicht nur die Textstruktur, sondern auch das dem Genre eigene Spiel zwischen unterschiedlichen Erzählformen (Traum, Utopie, Leserbrief et cetera) berücksichtigt. Genannte Personen, Orte und Werke wurden identifiziert und thematische Schlagworte vergeben. Der auf diese Weise annotierte und mit zusätzlichen Informationen angereicherte Text ermöglicht umfangreichere Analysen als "reiner" Text. Diese Form der elektronischen Textrepräsentation erlaubt es nun, im Vergleich zu einem Text ohne semantische Informationen, zusätzlich auf unterschiedliche Phänomene zuzugreifen.
Ein guter Zeitpunkt also, um nach knapp zehn Jahren Projektlaufzeit in die Vogelperspektive zu wechseln und die mittlerweile zu einer beachtlichen Größe angewachsene Textsammlung von Zeitschriften aus ganz Europa mit distant reading zu untersuchen. In dem von der Österreichischen Akademie der Wissenschaften und CLARIAH-AT finanzierten Projekt Distant Spectators. Distant Reading for Periodicals of the Enlightenment (DiSpecs) wurde das bestehende Projektteam um Expertinnen und Experten des Institute of Interactive Systems and Data Science der Technischen Universität Graz und des Know-Center Graz erweitert. Nun werden die Zeitschriften hinsichtlich ihrer Themen, stilistischer Merkmale und Stimmungsbilder untersucht, um Gemeinsamkeiten und Unterschiede auf automatisierte Weise zu identifizieren.
Sammlungen aus der Distanz betrachtet
Für solche Entdeckungsreisen durch Textsammlungen gibt es je nach gewünschtem Ankunftsziel viele Wege, wie etwa die in DiSpecs angewendeten Methoden der explorativen Datenanalyse (statistische Auswertung von Daten), der Stilometrie (stilistischer Vergleich von Texten), der Sentimentanalyse (Identifizierung von Meinungen sowie positiver und negativer Stimmung) und des Topic Modeling (Entdecken versteckter semantischer Strukturen, wie etwa Themen). Alle diese Analysemethoden haben schon lange vor unserem Projekt ihre Nützlichkeit bewiesen. Beispielsweise wurde durch Stilometrie ein wichtiger Beitrag zur ewigen Debatte über die Autorschaft der Shakespeare’schen Stücke geleistet und bestätigt, dass zum Beispiel sowohl Teile von Henry VI, als auch Henry VIII von anderen Autoren geschrieben wurden. Auch besteht dank Stilometrie heute kein Zweifel daran, dass sich hinter dem Pseudonym Robert Galbraith und seinem Roman Der Ruf des Kuckucks die berühmte J. K. Rowling verbirgt, wie die Harry Potter-Autorin auch bestätigt hat.
Es werden aber nicht nur literarische Werke distanziert betrachtet. Nahezu alle medialen Ressourcen, die in einem ausreichenden Umfang vorliegen und maschinell lesbar sind, können so analysiert werden: Twitter-Meldungen, historische Dokumente, Drehbücher, ja sogar Bilder, Audioaufnahmen und Filme. Wissenschaftliche Arbeiten können auf Plagiate untersucht, Persönlichkeitsprofile durch die Analyse von Briefen oder Tagebüchern erschaffen, oder auch neue Geschäftsstrategien durch die Analyse von Produkt-Bewertungen entwickelt werden. In DiSpecs drehen sich jedoch alle Fragen um das historische Zeitschriftengenre der Moralischen Wochenschriften.
Von Wörtern zu Zahlen, von Zahlen zu Schlussfolgerungen
Der erste Schritt war es, einen Überblick über den Datenbestand zu bekommen: Dank der XML-Annotation konnten mittels explorativer Datenanalyse statistische Werte errechnet und visualisiert werden, wie etwa die Anzahl der Zeitschriften pro Sprache, die durchschnittlichen Textlängen, die Häufigkeit der zuvor händisch vergebenen Schlagwörter, usw. Ein Mehrwert der Analyse war nicht nur die Evaluierung und Veranschaulichung des Bestandes, sondern auch das Entdecken und Ausbessern der Fehler in der manuellen Annotation, um somit die Qualität der Quellen für nachfolgende Untersuchungen – egal ob close oder distant – deutlich zu verbessern.
Worum geht es in den Texten?
Die erste Frage, die sich bei einem derart umfangreichen Material stellt, ist: Worum geht es in diesen Texten eigentlich? Das könnten zwar auch die händisch vergebenen Schlagwörter beantworten, aber je größer das Korpus, desto zeitaufwändiger – und daher oft nicht leistbar – die Verschlagwortung. Bei DiSpecs wurde neben der Auswertung der Schlagwörter auch Topic Modeling eingesetzt, um vorkommende Themen mittels maschinellen Lernens zu erkennen. Dieses Verfahren weist Wörter, die häufig zusammen vorkommen, einem gemeinsamen Topic zu. Meistens kann man aus einem derart maschinell definierten Topic ein Thema herauslesen, wie etwa Frauenmode, wenn Kleid, Dame, Anschein, und Farbe als Stichwörter vorkommen. Manchmal sind es auch nur strukturelle Merkmale, wie etwa Wörter einer bestimmten Fremdsprache, häufig zusammen vorkommende Personennamen oder ähnliches.
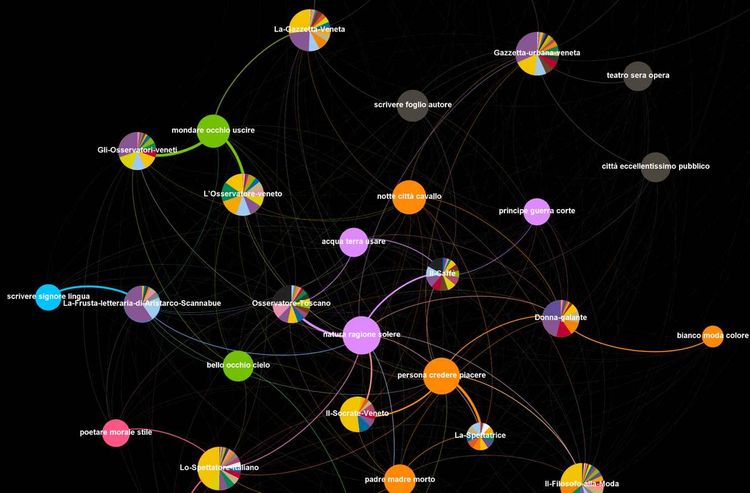
Somit ist es anhand verschiedener Visualisierungsmöglichkeiten wie Heatmaps, Netzwerken, Linien- oder Balkendiagrammen möglich, die Verteilung der Themen über die Zeit zu beobachten, Vergleiche mit der händischen Verschlagwortung zu machen sowie thematische Ähnlichkeiten und Unterschiede zwischen den einzelnen Texten und Textgruppen zu erkennen. Ein Beispiel dafür wäre der Ausschnitt aus einem Netzwerk aus Zeitschriften und den mit Topic Modeling gefundenen Themen: Mehrfarbige Zeitschriften-Knoten beinhalten Informationen zu den händisch vergebenen Schlagwörtern und sind mit den einfarbigen Themen-Knoten aus dem automatisierten Verfahren Topic Modeling je nach Wahrscheinlichkeit des Vorkommens über entsprechend schwache oder starke Kanten verbunden. Die Darstellung zeigt zum Beispiel die thematische Nähe dreier Zeitschriften von Gasparo Gozzi (Gli Osservatori veneti, L’Osservatore veneto und La Gazzetta Veneta) im italienischen Subkorpus der Edition Die "Spectators" im internationalen Kontext.
Was sind die stilistischen Besonderheiten?
Eine weitere Frage, die sich bei der Auseinandersetzung mit den Texten stellt, ist jene nach stilistischen Eigenheiten der individuellen Zeitschriften. Wie komplex ist das verwendete Vokabular und wie können anonyme Autorinnen und Autoren identifiziert werden? In den Moralischen Wochenschriften wird bewusst mit der Autorschaft gespielt: Statt ihre wahre Identität preiszugeben, werden fiktive Charaktere als Autoren eingeführt. Dieser Umstand macht sowohl auf die wahre Identität der anonymen Autorinnen und Autoren sowie der Übersetzerinnen und Übersetzer, als auch auf gemeinschaftlich verfasste Texte neugierig. Stilometrische Verfahren basieren auf statistischen Verteilungen von Wörtern und Textmerkmalen und ermöglichen damit, Texte miteinander zu vergleichen und die "Distanz" zwischen Texten zu bestimmten.
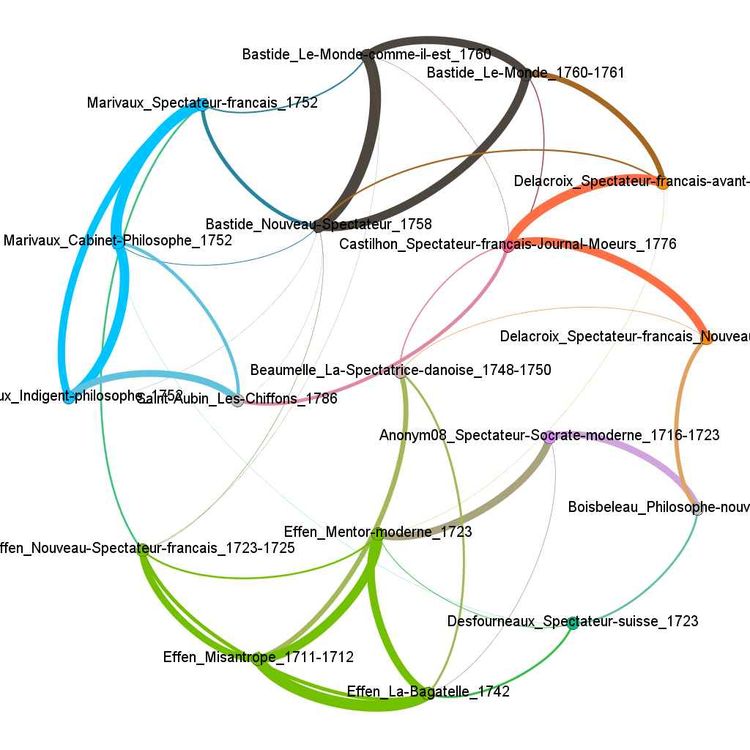
Eine Einschränkung bei der Anwendung dieser Methode auf die Moralischen Wochenschriften liegt im Mangel an Vergleichstexten einzelner Autorinnen und Autoren und in den relativ kurzen Texten. Durch die Anwendung stilometrischer Verfahren konnten dennoch signifikante Unterschiede bezüglich der Komplexität der Grammatik und des Vokabulars bei einzelnen Zeitschriften, Autorinnen und Autoren sowie den Themen ausgemacht werden. Zudem wurde eine lang anhaltende Kontroverse über die Autorschaft der anonym publizierten Übersetzung des englischen The Spectator ins französische, Le Spectateur ou le Socrate moderne, wieder aufgegriffen. Die Grafik zeigt eine Visualisierung der Ergebnisse aus einer Cluster-Analyse – einem Verfahren zur Entdeckung von Ähnlichkeiten – der französischen Zeitschriften. Ähnliche Zeitschriften sind durch dickere Kanten miteinander verbunden. Somit lassen sich auch anonyme Werke verorten.
Welche Stimmungsbilder werden vermittelt?
Schließlich stellt sich die Frage nach dem Stimmungsbild, das unter Einsatz literarischer Stilmittel über die Zeitschriften vermittelt wird. Welche Personen, Ereignisse und Themen standen im Fokus des Publikumsinteresses? Wurde eher positiv oder negativ über sie gesprochen? Sind Zeitschriftentexte über Mode und Familie in einem positiveren Ton verfasst als Texte über Politik? Diese Fragen lassen sich mittels Sentimentanalyse untersuchen. Eine besondere Herausforderung stellen dabei historische literarische Texte dar, sind doch die Methoden bislang vorrangig auf englischsprachige Social-Media-Texte und Produktrezensionen zugeschnitten.
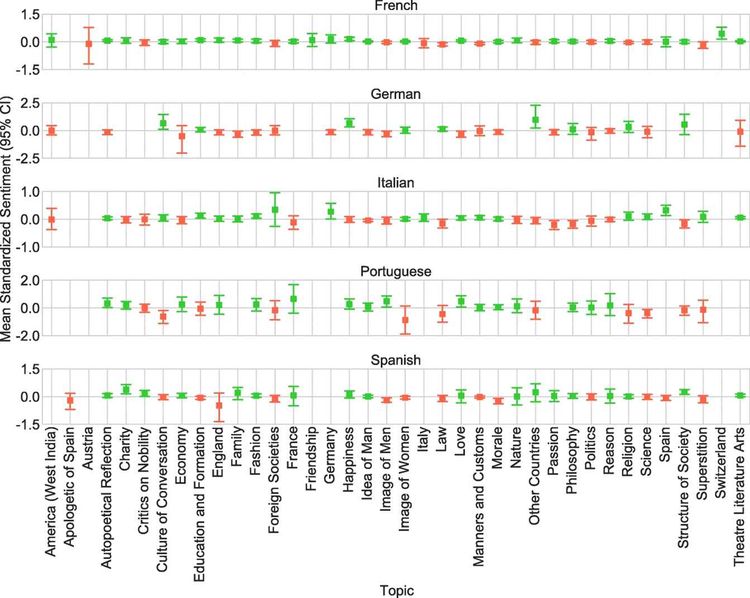
Die meisten Verfahren basieren auf Wortlisten, deren positive, neutrale oder negative Tendenz bekannt und allgemein anerkannt ist und mit deren Hilfe Texte beziehungsweise Textabschnitte entsprechend kategorisiert werden können. Doch auch hier ist Vorsicht geboten und jedes Wort in seinem Kontext zu betrachten: Verneinungen oder Bedeutungsverschiebungen können die Tendenz eines Wortes beeinflussen und sogar ins Gegenteil umkehren. In den Analysen zeigte sich zum Beispiel, dass in der Darstellung von Religion keine einheitliche Linie festzustellen ist, während gegenüber der Politik eine durchgehend kritische Haltung eingenommen wird. Zwischenmenschliche Beziehungen hingegen werden positiv dargestellt, was sich mit der eigentlichen Zielvorstellung der Zeitschriften, nämlich der Steigerung der Moral ihrer Leserinnen und Leser, deckt. Das zeigt auch die Visualisierung der durchschnittlichen Sentiment-Werte manuell vergebener Schlagwörter in den Moralischen Wochenschriften, sortiert nach Sprache. Grüne Box-Plots repräsentieren positive und rote negative Tendenzen.
Distant Reading unter der Lupe
Die beschriebenen digitalen Verfahren sind für den Umgang mit großen Textmengen praktisch und nützlich. Sind die Abläufe einmal vollständig entwickelt und angepasst, können sie mit erweiterten oder korrigierten Daten problemlos wiederholt werden. Sie beleuchten den Forschungsgegenstand aus einem Blickwinkel, der für nicht-digitale Ansätze nur schwer erreichbar ist. Nichtsdestotrotz bringen sie auch Kritik und Herausforderungen mit sich. Die Kritik richtet sich etwa auf den unüberwachten maschinellen Lernablauf mancher Methoden, wie etwa Topic Modeling. Da sich solche Algorithmen das Wissen über die analysierten Gegenstände selbst beibringen, können die Ergebnisse von einem Ablauf zum anderen variieren und sind nicht vollkommen nachvollziehbar oder gar reproduzierbar.
Dieser black box-Effekt verstärkt sich durch das häufig mangelnde interdisziplinäre Hintergrundwissen der Forschenden, was uns zur ersten Herausforderung bringt: Während den Geisteswissenschafterinnen und Geisteswissenschaftern manchmal das technische Know-how fehlt, ist den informationstechnisch Erfahrenen das Forschungsmaterial nicht immer ausreichend bekannt. Denn distant reading erfordert gleichzeitiges Wissen über die Statistik, das Programmieren, das Interpretieren und Visualisieren von Ergebnissen sowie über das erforschte Material, um die Prozesse evaluieren und die Ergebnisse verstehen zu können. Im Idealfall sind es daher wie in DiSpecs interdisziplinäre Teams, bestehend aus Forscherinnen und Forschern der Literaturwissenschaften, aus den Data Sciences und den digitalen Geisteswissenschaften, die an verschiedene Fachgebiete anknüpfen und ihre Expertisen zusammenführen können. Weitere Herausforderungen liegen in mangelnden Software-Lösungen und Ablaufszenarien für die breite Vielfalt an geisteswissenschaftlichen Anwendungsfällen, was vor allem bei historischen Texten oft der Fall ist, sowie in den oft nicht ausreichend strukturierten oder im geringen Umfang vorhandenen Daten.
Die Kombination aus unterschiedlichen distant reading-Methoden soll die Forschung zu den Moralischen Wochenschriften weiter anregen und neue Perspektiven eröffnen. Durch die Betrachtung der Zeitschriften aus der ‚Ferne‘ werden Gemeinsamkeiten und Auffälligkeiten offensichtlich gemacht, die wiederum Fachwissenschaftlerinnen und Fachwissenschaftler einer genaueren Untersuchung unterziehen müssen, um neue Erkenntnisse über dieses bedeutende Kulturerbe der Aufklärungszeit zu gewinnen. Gerade in Zeiten eines Social-Media-Überangebots scheint ein Blick zurück auf journalistische Meilensteine der Meinungsbildung und Meinungsverbreitung lohnend. (Sanja Sarić, Martina Scholger, 30.6.2021)
Literatur
- Ertler, Klaus-Dieter; Fuchs, Alexandra; Fischer-Pernkopf, Michaela; Hobisch Elisabeth; Scholger, Martina; Völkl, Yvonne (2011–2021): The Spectators in the international context.
- Geiger, Bernhard; Glatz, Christina; Hobisch, Elisabeth; Koncar, Philipp; Sarić, Sanja; Scholger, Martina; Völkl, Yvonne (2019–2021): Distant Spectators. Distant Reading for Periodicals of the Enlightenment.
- Koncar, Philipp; Fuchs, Alexandra; Hobisch, Elisabeth; Geiger, Bernhard C.; Scholger, Martina; Helic, Denis (2020): Text sentiment in the Age of Enlightenment: an analysis of spectator periodicals. Appl Netw Sci 5, 33.
- Lau, Johannes (2021): KI in den Geisteswissenschaften: Der Mensch füttert, die Maschine kaut.
- Karsdorp, Folgert; Kestemont, Mike; Riddell, Allen (2021): Humanities Data Analysis. Case Studies with Python. Princeton: Princeton University Press.
- Moretti, Franco (2013): Distant Reading. London, New York: Verso.
- Schöch, Christof (2017): Quantitative Analyse. In: Digital Humanities. Eine Einführung. Hrsg. von Fotis Jannidis, Hubertus Kohle und Malte Rehbein. Stuttgart: J.B. Metzler, S. 279–298. ISBN: 978-3-476-05446-3.
Links
- Geisteswissenschaftliches Asset Management System (GAMS)
- Institut Zentrum für Informationsmodellierung - Austrian Centre for Digital Humanities
- Institute of Interactive Systems and Data Science
- Institut für Romanistik
Weitere Beiträge im Blog