Im Gastblog beschreibt Sophie Kaltenleithner, wie das Open-Source-Tool CaTabRa in der Medizin hilfreich sein kann.
Daten werden mittlerweile in fast allen Lebensbereichen gesammelt – sei es beim Online-Shopping, in Fitness-Apps oder beim Produktionsprozess. Ein häufiges Ziel davon ist es, automatisch Vorhersagen zu treffen: Welchen Zielgruppen soll mein Produkt vorgeschlagen werden? Wie viel Gewichtsabnahme kann ich erwarten, wenn ich täglich eine Runde laufe? Wann muss ich die Verschleißteile meiner Maschinen tauschen, um möglichst kurze Stillstandszeiten zu haben? Solche Vorhersagen bedürfen komplexer Analysetätigkeiten und technischer Expertise. CaTabRa schafft hier Abhilfe: CaTabRa ist ein Open-Source-Tool zur automatisierten Analyse von tabellarischen Daten und Entwicklung von Vorhersagemodellen.
Anwendungsbeispiel aus der Medizin
Kann man Covid-19 anhand von Werten eines Standard-Bluttests diagnostizieren? Mit dieser Frage beschäftigten sich Forscherinnen und Forscher der Johannes-Kepler-Universität Linz, des Kepler-Universitätsklinikums Linz und der RISC Software GmbH1. Ziel war es, Covid-19-Infektionen aus routinemäßig durchgeführten Labortests nachzuweisen, um so eine große Anzahl von Patientinnen und Patienten schnell und ohne Mehraufwand testen zu können. Ähnlich gute Ergebnisse können auch allein mithilfe von CaTabRa generiert werden, wie im Folgenden demonstriert wird.
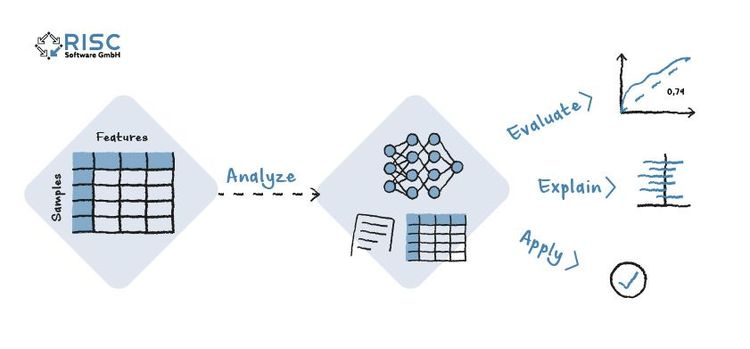
Ein typischer Workflow in CaTabRa besteht aus den folgenden vier Schritten:
- Analyze: erstellt Statistiken und trainiert Vorhersagemodelle.
- Evaluate: evaluiert die Modelle auf einem Testdatensatz, um ihre Qualität zu überprüfen.
- Explain: generiert Erklärungen für Modellentscheidungen in Form von Feature-Importance Scores.
- Apply: trifft Vorhersagen für neue Samples durch Anwenden der zuvor trainierten Modelle.
Die Qualität von Machine-Learning-Modellen hängt stark von den verwendeten Algorithmen und deren Konfigurationen ab. Diese können im Vorfeld nicht ohne weiteres festgestellt werden. CaTabRa setzt deshalb auf State-of-the-Art-AutoML-Methoden, um schnell und ohne großen manuellen Aufwand die richtige Konfiguration zu finden. AutoML steht für "Automated Machine Learning". Dabei werden komplizierte Optimierungsverfahren eingesetzt, um sich schrittweise der besten Lösung anzunähern.
Modellerklärung – Explainable AI
Da Entscheidungen von Black-Box-Machine-Learning-Modellen für Menschen nur schwer nachvollziehbar sind, ist es gerade in der Medizin wichtig, den Modellen nicht blind zu vertrauen. Oft ist etwa ein ungewollter Bias in den Daten vorhanden, der die Modelle dazu veranlasst, falsche Schlussfolgerungen zu ziehen. Wären in den Trainingsdaten etwa zufällig mehr Männer als Frauen an Covid-19 erkrankt, könnte das Geschlecht der Patientinnen und Patienten zu stark in die Entscheidung einfließen.
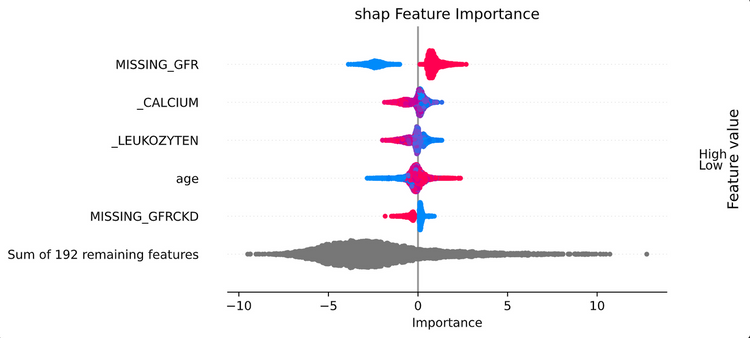
Deshalb erlaubt es CaTabRa, die Wichtigkeit von einzelnen Features (Blutwerte) festzustellen. Abbildung 2 zeigt die Feature-Importance Scores der Covid-19-Daten für die fünf wichtigsten Features. Beispielsweise deutet das Fehlen von Messungen der glomerulären Filtrationsrate ("MISSING_GFR"; ein Parameter, der vor allem die Nierenfunktion misst) auf eine Covid-19-Infektion hin. Auch hohes Alter scheint für den verwendeten Datensatz ein Indikator zu sein.
Modelle des maschinellen Lernens gehen meist davon aus, dass neu vorherzusagende Daten der Verteilung der ursprünglichen Trainingsdaten entsprechen. In der Realität trifft dies aber nicht immer zu. Im Fall von Covid-19 könnten sich durch die rasche Verbreitung und das Entstehen von Mutationen die neuen Daten zu sehr von den alten unterscheiden. Vorhersagen kann in solchen Fällen nicht mehr vertraut werden. Deshalb bietet CaTabRa Funktionalitäten, um solche Unterschiede festzustellen.
Bei der Vorhersage von Covid-19 ist Vorsicht geboten
Was aus den Ergebnissen der originalen Publikation hervorgeht und sich auch bei Anwendung von CaTabRa zeigt: Bluttests sind ein relativ guter Indikator dafür, ob eine Person an Covid-19 erkrankt ist. Allerdings gilt dies nur so lange, wie man sich sicher sein kann, dass sich die Eigenschaften des Virus und dessen Verbreitung nicht zu stark ändern. Deshalb sollten Machine-Learning-Modelle kontinuierlich auf aktuelle Daten überprüft und gegebenenfalls neu trainiert werden. (Sophie Kaltenleithner, 14.6.2023)