Schlag auf Schlag geht es derzeit bei Google im Bereich künstliche Intelligenz (KI). Nachdem man erst in der Vorwoche eine Fülle an Neuerungen um das eigene KI-Modell Gemini präsentiert hat, gibt es nun bereits die nächste Generation des großen Sprachmodells (LLM) sowie eine Reihe Ankündigungen für jene, die das Ganze als Basis für eigene Software nutzen wollen.
Effizienz
Gemini 1.5 soll gleich in mehrerlei Hinsicht einen signifikanten Fortschritt gegenüber dem erst Anfang Dezember vorgestellten Gemini 1.0 darstellen. Einer davon ist die Performance, die Nutzung der neuen LLM-Generation soll also erheblich effizienter sein. Und das sowohl im Betrieb als auch beim Training, wie Google betont.
Das erste Gemini-1.5-Modell, das Google nun vorstellt, ist Gemini Pro 1.5, also das mittelgroße von Googles LLMs. Dessen Leistungsfähigkeit soll auf dem Niveau des erst in der Vorwoche freigegebenen Gemini Ultra 1.0 – also des größten Modells von Google – liegen, das aber eben mit einer deutlich besseren Performance.
Als einen zentralen Grund für diesen Fortschritt verweist Google auf die "Mixture of Experts"-Architektur von Gemini 1.5. Das LLM ist dabei in mehrere auf unterschiedliche Aufgaben optimierte Bereiche aufgeteilt, das erhöhe die Effizienz massiv.
Deutlich längeres Verständnis
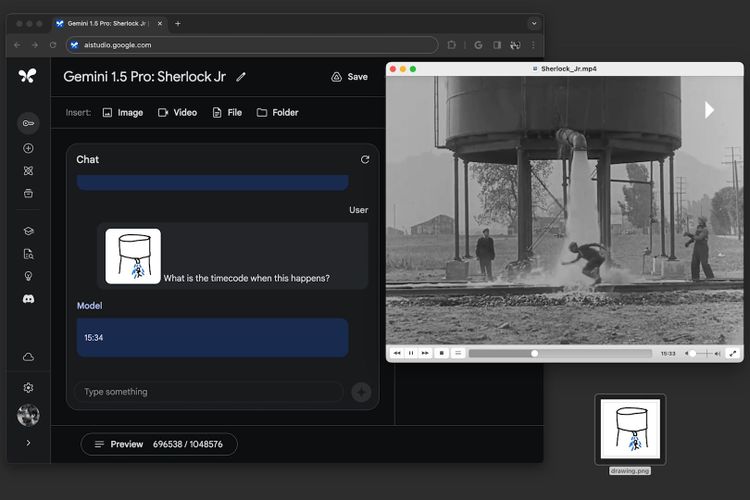
Doch Gemini 1.5 hat noch einen weiteren Vorteil: Es soll ein wesentlich längeres Verständnis des Kontextes einer Diskussion haben, als es bei bisherigen LLMs der Fall ist. Von bis zu einer Million Tokens spricht Google, bei Gemini 1.0 waren es noch 32.000 Tokens, der Konkurrent GPT-4 Turbo von OpenAI ist auf 128.000 Tokens beschränkt.
In der Praxis bedeutet dies, dass Gemini 1.5 wesentlich größere Datenmengen in einem Durchgang verarbeiten kann. Von bis zu einer Stunde Video, 30.000 Zeilen Code oder Texten mit 700.000 Wörtern spricht Google. Damit soll es Gemini künftig möglich sein, wesentlich größere Zusammenhänge zu erfassen und gerade mehrere Modalitäten – also Text, Bild, Ton oder auch Video – übergreifende Zusammenhänge ziehen zu können.
Derzeit beschränkt man das Kontextfenster bei Gemini 1.5 Pro zwar von Haus aus noch auf 128.000 Tokens, ausgewählte Tester sollen aber ab sofort Zugriff auf das volle Kontextfenster erhalten. Für andere soll dies nach und nach erweitert werden.
Vertex AI
Parallel dazu gibt es eine Reihe von Ankündigungen für Entwicklerinnen und Entwickler, die Gemini für eigene Anwendungen nutzen wollen. So ist Gemini 1.0 Pro ab sofort für alle Kunden von Vertex AI in der Google Cloud verfügbar. Wer Gemini Ultra 1.0 nutzen will, muss das hingegen noch beantragen. Gemini 1.5 Pro bleibt wiederum vorerst noch "privat", wird also mit ausgewählten Partnern getestet, so wie es bisher bei Gemini 1.0 der Fall war. Wann eine weitere Öffnung folgt, verrät man noch nicht. Ausprobiert werden kann all das auch via der webbasierten Entwicklungsumgebung Google AI Studio.
Zudem kündigt man das "Google AI Dart SDK for the Gemini API" an. Dabei handelt es sich um Entwicklerschnittstellen, um in Flutter oder Dart geschriebene Apps an Gemini anzubinden. Das soll die Erstellung entsprechender Programme für Android und iOS, aber auch für Web, Mac, Windows und Linux deutlich vereinfachen. Auch für Firebase gibt es neue Erweiterungen für die direkte Anbindung an Gemini. (Andreas Proschofsky, 15.2.2024)